LDR での『はてなブックマークエントリー情報取得API』利用について
以前から利用していた『ブックマーク件数取得 API』 (http://b.hatena.ne.jp/xmlrpc) と組み合わせて、ブックマークされている記事のコメントを自動的に表示するようにしてみました。
スクリプトの概要は、このようなものです:
// 全記事のブックマーク件数を取得
register_hook("after_printfeed", function(feed) {
(new XMLRPC).
proxy("http://b.hatena.ne.jp/xmlrpc").
call("bookmark.getCount", feed.items.map(function(v) { return v.link })).
result(print_hb_count);
});
// ブックマーク数が 1 以上のものを取り出す
function print_hb_count(res) {
res.responseText.replace(/<name>(.+?)<\/name><value><int>(\d+)/g,
function(_, link, num) {
num = parseInt(num);
if (num > 0) {
print(link, num);
print_hb_comment(link);
}
});
function print(link, num) {
...
}
}
// コメント出力
function print_hb_comment(link) {
GM_xmlhttpRequest({
method: "GET",
url: "http://b.hatena.ne.jp/entry/json/"+link.replace(/#/,"%23"),
onload: function(res) {
var json = eval(res.responseText);
print(json.bookmarks);
print_hss(json.screenshot);
}
});
function print(items) {
...
}
}
// スクリーンショット表示 (optional)
function print_hss(screenshot) {
...
}JSONP (http://b.hatena.ne.jp/entry/json/?url=URL&callback=CALLBACK) と JSON (http://b.hatena.ne.jp/entry/json/URL) 両方の API が公開され、特にクロス・ドメインでの利用という文脈で JSONP API への注目が集まっているわけですが、GM_xmlhttpRequest が使える環境であれば普通に JSON API を使うのが楽です。
以前から http://r.hatena.ne.jp/entry/bcomment?entryurl=URL&flag=1 という、コメントを HTML 形式で返してくれる API はあったのですが、好みの整形が可能になったり、コメント以外の情報を得られるという点で、JSON[P] API は意義があると思います。
また、情報を一元的に得られるわけですから、これまで別個に行っていたことを一箇所に集約し易くなるという利点があります。もちろんブックマーク件数も取得できますから (json.count)、連続的なリクエストに配慮しさえすれば、『ブックマーク件数取得 API』の利用にこだわる必要も特に無いと言えるでしょう。
参考:
はてなブックマークエントリー情報取得API
http://b.hatena.ne.jp/entry/http://b.hatena.ne.jp/entry/json/http://d.hatena.ne.jp/otsune/20060614/mixihate
UserJS Mania - livedoor Readerにはてなブックマークのコメントを表示する
追記:
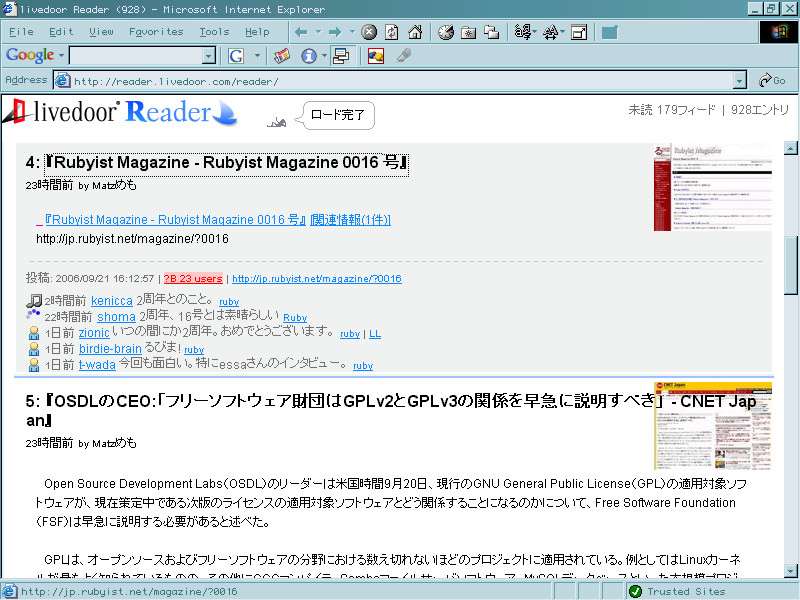
画像の解説を忘れてました。
表示されているのは 1470.net のフィード (Matzめも) です。
ここの
下の方に表示されている記事は、id:reinyannyan:20060825:p1 の方法で自動的に全文表示されたものです。これも before_printfeed フックを使っています。
(?B 関連の処理は after_printfeed イベントを使っています)
Unix のパイプのような感じで、フィルターされたデータを次々と渡して、順序良く処理しているわけです。
ここで問題なのは、同じイベント・フックを複数回使う場合に、このように流れをコントロールすることが出来るだろうか、ということです。
私のように素の IE で一つの .js ファイルで拡張している場合は問題無いんですが、小さな user.js ファイルを多く使用するモデルにおいては、このような協調が困難な場合が出てくるんじゃないでしょうか?
といったことを画像で表現したかったのでした。