Unix シェル的なバックグラウンドでのタスク処理
bash> command &
みたいに、バックグラウンドで関数を呼び出して、値が必要になった時に表に戻す、というイディオムを思い付きました。
(define (& t)
(let ((c (make-channel)))
(thread
(lambda ()
(channel-put c (t))))
(lambda (k)
(k (channel-get c)))))使い方
(let ((%
(& (lambda () some hard work))))
...
(% values))ごちゃごちゃしがちなスレッドの同期処理がスッキリ書けて良いと思います。
追記:
lambda が面倒なので、マクロにしてみました:
(define-syntax &
(syntax-rules ()
((& e)
(let ((c (make-channel)))
(thread (lambda () (channel-put c e)))
(lambda (k) (k (channel-get c)))))
((& e1 e2 ...)
;; Concurrent version of `begin'
(let ((l (list (& e1) (& e2) ...)))
(lambda (k)
(let loop ((l l))
((car l)
(lambda (v)
(if (null? (cdr l))
(k v)
(loop (cdr l)))))))))))式が複数有る場合、それぞれをスレッド下で処理するようにしています。begin と同様に、最後の式の値だけ得られるようになってます。
ニコ動のコメントをREPLで
最近ニコ動に上がっている作業用BGMとか、音声だけで楽しめるものをWinampで聴く、ということをしているんですが

(Scheme でローカルサーバー -> localhost:2525/?id=VIDEO_ID 的なURLをWinampで再生 -> にこさうんど or にこみみのキャッシュを探す -> mp3をWinampに転送、という流れで。タイトルにダブルクォートが付いているのがウェブ上のリソースという印です。Content-Disposition の filename フィールドを表示しています)
コメントが見れないのがちょっと寂しくなってきたので、REPLに表示してみました:
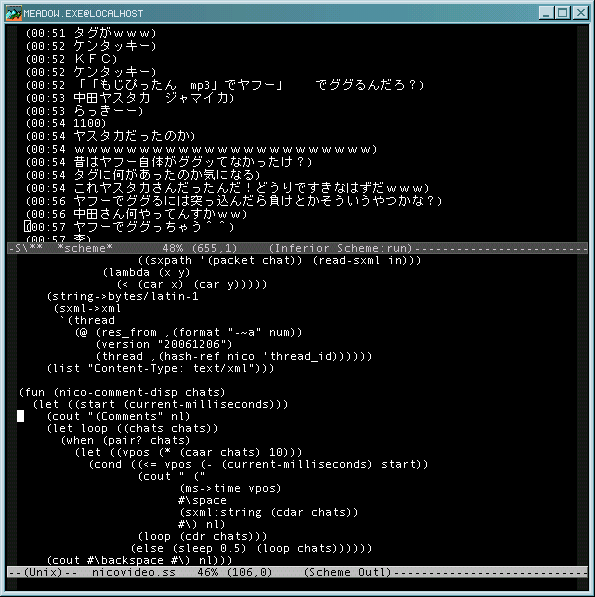
(上のとは別の動画です)
コメントXMLのタイミング情報の単位がちょっと変わっていて (10ミリ秒) 戸惑いました。あと、XMLの取得に若干時間がかかってしまい、再生から少し送れて表示されてしまうという欠点があるんですが、プレイヤー側で時間調整すれば一応時間通りに表示することができます。
追記:
コメントの出力形式を変えてみました。歌詞職人のコメだけ抽出、みたいなことも出来たり…
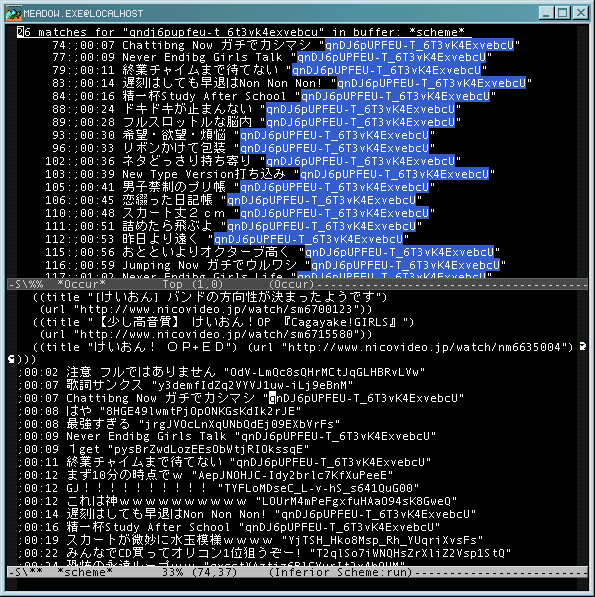
あと、コメント表示が再生開始のタイミングと同期できない問題は、カリー化関数の部分評価の機能により思いがけず解決しました。
(fun (nico-comment-disp ignore? chats)
(let ((start (current-milliseconds)))
(let loop ((chats chats))
(if (pair? chats)
(receive (vpos chat)
(values (* (caar chats) 10) (cdar chats))
(cond ((ignore? chat)
(loop (cdr chats)))
((<= vpos (- (current-milliseconds) start))
(cout #\; (ms->time vpos)
#\space (sxml:string chat)
" \"" (user-id chat) #\" nl)
(loop (cdr chats)))
(else (sleep 0.333) (loop chats))))
(cout "; end of comments" nl)))))この関数を、先に第1引数に適用してからXMLを取りに行くようにしたところ、startの値がその時点 (再生開始時) でのミリ秒に固定されるので、フルに適用されるまでの時間幅が吸収されるようになったんです。
まぁ、startの値を関数のパラメータにしておけば良かった話なんですが…
Scheme から Emacs のコマンドを実行
私はよく Scheme のプログラムを Emacs 上で実行するんですが、elscreen で裏に回していたりして *scheme* バッファが見えない時に、何かユーザーの注意や介入が必要な事態が起こっていることがあります (入力を促す、等)。
そんな時、外部プログラムを起動するとか、ffi で CD トレイを開くとか、その旨を知らせる方法はいくらでも有るわけですが、せっかく Emacs がそこにあるんだから (beep) の一つも eval 出来ないでどうする、ということで考えてみました。
Scheme と Emacs の間には接続が張られているわけですから、そこにコマンドを流し込み、フック関数でモニターすれば良い、ということで、出来たのがこちら:
(add-hook 'inferior-scheme-mode-hook
(lambda ()
(add-hook 'comint-preoutput-filter-functions
(lambda (s)
(if (string-match "^(tell-emacs \\(.*\\))" s)
(save-excursion
(prin1
(eval
(car
(read-from-string (match-string 1 s)))))
"> ")
s))
nil t)))目的のフックがすぐ見つかったので案外易しかったです。"(tell-emacs " で始まる行を見つけたらS式を文字列として取り出し、read-from-string で S式化してから eval します。
さらに、Scheme 以外でも使えるようにマクロ化してみました (elisp にはクロージャが無いので):
(eval-when (load)
(defmacro connect-to-emacs (prompt)
`(add-hook 'comint-preoutput-filter-functions
(lambda (s)
(if (string-match "^(tell-emacs \\(.*\\))" s)
(save-excursion
(prin1
(eval
(car
(read-from-string (match-string 1 s)))))
,prompt)
s))
nil t)))プロンプトを言語ごとに設定できるようになっています:
(add-hook 'inferior-scheme-mode-hook
(lambda () (connect-to-emacs "> ")))
(add-hook 'shell-mode-hook (lambda () (connect-to-emacs "")))上記を .emacs に追加しておくと、Scheme プログラム中で
(display '(tell-emacs (beep)))
のように出力するか、あるいはプロンプトで
> '(tell-emacs (beep))
と評価することで、任意の Lisp 式を Emacs に送信できるようになります。
当然ながら
'(tell-emacs
(comint-send-string (scheme-proc)
"'(tell-emacs (beep))"))てなことも出来ます。
なお、Lisp 系以外の場合は式を文字列としてプリントする方法を取ってください。シェルモードの例:
echo "(tell-emacs (comint-send-string (scheme-proc) \"'(tell-emacs (beep))\"))" | cat
もっと騒がしい通知の例 (Scheme + Cygwin):
'(tell-emacs
(comint-send-string (save-window-excursion (shell))
"cat /dev/urandom > /dev/audio\n"))一見回りくどいですが、Windows 上の MzScheme からシェルを呼び出すよりちょっと楽だったりします。
ぜひお試しあれ。
Implicit Function Currying with Automatic Partial Evaluation
関数の部分適用と部分評価を自動的に行うマクロの実装を、日本語と Scheme で示していきます。
動機
前回 fun と fn という、Standard ML ライクなカリー化関数の構文をご紹介しました。とても便利で既に多用しているんですが、一つどうしても気になるのは、コードが無駄にコピーされてしまう点です。
例えば
(fn (x y z) (* (+ x y) z))
という関数は次のように展開されてしまいます:
(case-lambda
((x)
(case-lambda
((y)
(lambda (z)
(* (+ x y) z)))
((y z)
(* (+ x y) z))))
((x y)
(lambda (z)
(* (+ x y) z)))
((x y z)
(* (+ x y) z)))元の定義の本体部分があちこちに散らばっていますよね。これだとせっかく部分適用ができても、完全に適用されるまで本体の評価が持ち越されることになります。
この関数の場合、x と y が与えられた時点で (+ x y) は計算可能ですから、その部分は評価しちゃって欲しいところです。このままだと部分適用した関数を map 等で何度も利用する場合にあまり嬉しくありません。
具体的には、こういう式展開をしてくれれば良いなと思うわけです:
(case-lambda
((x)
(case-lambda
((y)
(let ((g1 (+ x y)))
(lambda (z)
(* g1 z))))
((y z)
(* (+ x y) z))))
((x y)
(let ((g2 (+ x y)))
(lambda (z)
(* g2 z))))
((x y z)
(* (+ x y) z)))
方針
まず何をどうするかが問題ですが、基本的には上の展開例のように、与えられた引数のみに依存する式を関数本体から探し出し、評価し、その値で置き換えてやれば良いと思われます。
ただ、実際には評価を行うのは実行時なので、評価を行うための let 構文を埋め込むというコード変形を行うことになります。
例えば g1 の部分に注目していただくと、そこのスコープでは x と y が参照可能ですから、本体から x と y の計算式を抜き取り、ラムダの外に追い出して評価しています。これで一度だけの評価で済みますね。
この一度だけというのがポイントで、もし if 文の中にあってプログラム実行中に一度も評価されない可能性がある式は、部分評価の対象外とすべきでしょう。
実装
ところで、Lisp のプログラムと言えばリスト (ツリー) ですよね。ツリーの探索や置換と言えば、zipper を思い出します。ということで、zipper で使ったツリー探索の仕組みをコード変形に適用することにします。
こういうのです:
;; Adapted from: http://okmij.org/ftp/Scheme/zipper-in-scheme.txt
(define (map* f l)
(if (not (pair? l))
l
(cons (f (car l)) (map* f (cdr l)))))
(define (depth-first handle tree)
(cond ((not (pair? tree)) tree) ; an atom
((handle tree) => values)
(else ; the node was not handled -- descend
(map* (lambda (kid)
(depth-first handle kid))
tree))))depth-first を使って式を探索し、置換可能な部分が見つかればその都度変数で置き換えていく、というのが基本戦略となります。
ただ、関数本体はマクロのパターンマッチで取得するので、初めはシンタックス・オブジェクトというデータ型になっています。それをツリー構造に展開する関数が必要です:
(define (syntax->tree x stop?)
(cond ((stop? x) x)
((syntax? x)
(syntax->tree (syntax-e x) stop?))
((pair? x)
(cons (syntax->tree (car x) stop?)
(syntax->tree (cdr x) stop?)))
(else x)))使用例:
> (syntax->tree #'(* (+ x y) 1) identifier?) (#<syntax::229> (#<syntax::232> #<syntax::234> #<syntax::236>) 1)
depth-first とは別に、ツリー内部を検索する関数も必要になります:
(define (stx-search p? stx)
(cond ((p? stx) #t)
((stx-pair? stx)
(or (stx-search p? (stx-car stx))
(stx-search p? (stx-cdr stx))))
(else #f)))(stx-pair? とかは PLT Scheme のライブラリ関数です)
「まだ与えられていない引数」および「関数本体で導入されるレキシカル変数」は参照することが出来ないため、これらに依存する式は評価できません (コンパイル時に unbound variable エラーになります)。
なので、置換可能な式を探索する際に、式の中に参照不可能な変数が含まれていないかチェックしなければなりません。
そしてそのチェックのためには、予めレキシカル変数をコードから抽出しておく必要があります:
(define (match-vars stx)
(kernel-syntax-case stx #f
((define-values (v ...) e ...)
(syntax->list #'(v ...)))
((#%plain-lambda (v ...) e ...)
(syntax->list #'(v ...)))
((case-lambda (v e ...) ...)
(append-map syntax-e (syntax->list #'(v ...))))
((let-values ((v x) ...) e ...)
(append-map syntax-e (syntax->list #'(v ...))))
((letrec-values ((v x) ...) e ...)
(append-map syntax-e (syntax->list #'(v ...))))
((set! v e) (list #'v))
(else '())))
(define (collect-vars stx)
(cond ((pair? stx)
(append (collect-vars (car stx))
(collect-vars (cdr stx))))
((syntax? stx)
(append (match-vars stx)
(collect-vars (syntax-e stx))))
(else '())))関数本体のコードに collect-vars を適用すると、再帰的にレキシカル変数のリストが得られるようになっています。set! で変更される変数もついでに捕捉しておきます。
メイン部分に入っていきましょう。
(define-syntax (fn stx)
(syntax-case stx ()
((fn params . exp)
(kernel-syntax-case
(call-with-values
(lambda ()
(syntax-local-expand-expression #'(lambda params . exp)))
(lambda (stx _) stx))
#f
((#%plain-lambda params . exp)
(make-cases (cons #'begin
(map (lambda (e)
;; Keep protected exp intact
(if (protected? e)
e
(syntax->tree e identifier?)))
(syntax->list #'exp)))
(syntax->list #'params)
(collect-vars #'exp)))))))前のバージョンとの違いの一つは、パターンマッチで得た関数本体 (exp) を local-expand でフル展開しているところです。これは、receive とか and-let* のような派生構文を全て展開してコアの構文のみにするためです。おかげで match-vars の定義が楽になります。
ただ、これには少し厄介な問題も伴います。フルにマクロ展開をしてしまうと、モジュール内部のエクスポートされていない識別子が展開形の中に出てきてしまう場合があるのです。
この問題に対し、PLT Scheme では、そのような識別子を含む構文オブジェクトに封印のような仕掛けを施しており、少しでも手を加えると封印が破れたことが検知され、コンパイル・エラーが出るようになっています (参照: Fwd: module security)。
というわけで、封印の掛かっている構文オブジェクトは次の関数でチェックし、部分評価の対象から外さなければいけません。
(define (protected? stx)
(stx-search (lambda (x)
(and (syntax? x)
(syntax-property x 'protected)))
stx))カリー化定義の本体はこのようになりました:
(define (make-cases exp params locals)
(cond ((null? params) exp)
((null? (cdr params))
#`(lambda #,params #,exp))
(else
#`(case-lambda
#,@(map (lambda (i)
(let-values (((bound-params rest-params)
(split-at params (+ i 1))))
(if (null? rest-params)
#`(#,bound-params #,exp)
(let*-values
(((residue ev-binds)
(peval exp (append rest-params locals)))
((exp2)
(make-cases residue rest-params locals)))
#`(#,bound-params
#,(if (pair? ev-binds)
#`(let #,ev-binds #,exp2)
exp2))))))
(iota (length params)))))))peval という関数を呼び出している点が前回と異なります。residue と ev-binds という2値を返す関数です。後者はその部分適用の時点で評価可能な式と、それに束縛される変数の組のリストです。前者は部分評価をした後の、小さくなった関数本体を表します。
peval を再帰的に呼び出す度に残りの計算が少なくなっていく、ということが期待できるわけです。
(define (peval exp unbound)
(let ((binds '()))
(values (depth-first
(lambda (e)
(cond ((ignore-form? e) e) ;avoid descent
((side-effect? e) #f) ;just descend
((free-from? e unbound)
(let ((g (gensym)))
(set! binds (cons #`(#,g #,e) binds))
g))
(else #f)))
exp)
(reverse binds))))ここで depth-first の使い方を説明しておきましょう。
第1引数の関数で第2引数に含まれるノードを順次受け取っていきます。そして返値として #f を返せばノードに変更を加えず、それ以外の値を返すとノードがその値で置き換えられる仕組みです。
いずれの場合もそれ以降の探索は続行されるんですが、#f の場合はそのノードの下位ノードへと降りていくのに対し、#f 以外の場合は次のノードに進むという違いがあります。
peval においては、構文木の中から簡約可能な式を見つける上で、その下降とかスキップを適宜行っているわけです (if 文は無視して次に進む、等)。
そして簡約可能な式が見つかると、部分評価のためのバインディング #`(#,g #,x) を記録しつつ変数 g で置き換えていきます。
以下 depth-first 中の条件判断の関数です:
(define (operator exp)
(and (pair? exp)
(let ((x (car exp)))
(and (identifier? x)
(pair? (identifier-binding x))
(syntax-e x)))))
(define (application? exp)
(cond ((operator exp)
=> (lambda (op)
(and (eq? op '#%app)
(let ((proc (cadr exp)))
(if (syntax? proc)
(syntax-e proc)
proc)))))
(else #f)))
(define (free-from? exp unbound)
(and (application? exp)
(not
(stx-search (lambda (id)
(and (identifier? id)
(ormap (lambda (ng)
(or (bound-identifier=? ng id)
(free-identifier=? ng id)))
unbound)))
exp))))
(define (ignore-form? exp)
(let ((forms-to-ignore
'(if quote quote-syntax with-continuation-mark
#%top #%variable-reference)))
(cond ((operator exp)
=> (lambda (op) (memq op forms-to-ignore)))
(else #f))))
(define (side-effect? exp)
(let ((side-effecting-procs
'(dynamic-require sleep thread kill-thread
call/cc call-with-current-continuation
call-with-continuation-prompt
;; and much more ...
)))
(stx-search (lambda (e)
(cond ((application? e)
=> (lambda (op) (memq op side-effecting-procs)))
(else #f)))
exp)))実装は一応以上です。ソース: curry.ss
利用例
実例を手元で実際に動かしているものから抜粋します:
(fun (nicovideo user watch)
(login (lookup 'mail user) (lookup 'pass user))
(make-immutable-hasheq
(let ((vid (video-id watch)))
`((video_id . ,vid)
,@(let ((api-url (string->url (api vid))))
(call/input-url api-url
get-pure-port
(lambda (in)
;; We need to extend cookie with view history prior to
;; further activities
(view-page watch)
(form-urlencoded->alist (port->string in)))
(list (make-cookie-header api-url))))))))これはニコ動ダウンローダの一部で、セッションIDを取得して動画の情報を得る関数です。実際の動画やコメントのダウンロードには別の関数を組み合わせて使います。
カリー化により第1引数 (ユーザー情報の連想リスト) が先に与えられると、その時点で最初のログインの式が評価されます。したがって、このように
(map (compose nico-download
(nicovideo '((mail . "mail@address") (pass . "passwd"))))
'("http://www.nicovideo.jp/watch/sm5003587"
"http://www.nicovideo.jp/watch/sm2143250"
"http://www.nicovideo.jp/watch/sm5008319"))複数の動画を一気にダウンロードする時でも、ログインは1回で済むわけです。
部分評価が無ければ呼び出しの回数分だけログインしてしまうところですから、大きなメリットと言って良いでしょう。
問題点
最後に幾つか問題点を挙げておきます。
第1に、評価順の問題です。
begin のような構文であっても、式の並び順で評価が行われるとは限りません。簡約可能な式が後ろの方にあるとそれが先に評価されてしまう、という事が起こり得るわけです。
次に、副作用の問題があります。
ニコ動の例においては、ログインが1回で済むというのは一見望ましい振る舞いのように思えます。が、一般に副作用を起こす関数が1回の評価で良いのか、何度も評価されて欲しいのか、というのは実は非常に微妙な問題だと思います。
また、評価順の問題とも絡んで、副作用を伴う式が意図しない順序で評価されると、プログラムが正しく動作しなくなる事もあります。
第3に、継続や dynamic-wind 等の特殊な制御構造に干渉しないよう注意を払わなければなりません。
最後に、どこかで変更されるかもしれないグローバル変数やパラメータ、あるいはダイナミック変数をキャッシュしてしまう可能性も考慮する必要があるでしょう。
なお、これらは全てマクロの実装者側が留意すべき事柄であり、ユーザー側は何も考えなくても勝手に最適化が行われる、というのが理想です。
ML っぽいカリー化関数を定義するマクロ
ML とか Haskell のコードを読む時に私がどうしても憧れてしまうのが、自動的にカリー化定義される関数です。
Scheme にもカリー化関数を定義する構文自体は存在します (処理系にもよるでしょうが)。
例えば、このようなラムダ式のネストで定義された関数を
(define add3
(lambda (a)
(lambda (b)
(lambda (c)
(+ a b c)))))次のようなスタイルで短く書くことができるんです:
(define (((add3 a) b) c) (+ a b c))
でも全然自動的ではないですし、必ず定義した通りに適用しなければいけません:
(((add3 1) 2) 3)
2番目と3番目の引数を同時に与える、とかは出来ないわけです。
そこでちょっと知恵をひねりまして、case-lambda を使って、あらゆる関数適用のパターンに応じたラムダ式をあらかじめ作っておく、という方法を考えてみました:
(define-syntax (fun stx)
(define (make-cases vars body)
#`(case-lambda
#,@(for/list ((i (in-range (length vars))))
(let-values (((hd tl) (split-at vars (+ i 1))))
#`(#,hd
#,(if (null? tl)
body
(make-cases tl body)))))))
(syntax-case stx ()
((fun (fn v ...) e ...)
#`(define fn
#,(make-cases (syntax->list #'(v ...))
#'(begin e ...))))))これを使うと、
(fun (add3 a b c) (+ a b c))
という定義は以下のように展開されます:
(define add3
(case-lambda
((a)
(case-lambda
((b)
(case-lambda
((c) (begin (+ a b c)))))
((b c) (begin (+ a b c)))))
((a b)
(case-lambda
((c) (begin (+ a b c)))))
((a b c) (begin (+ a b c)))))コードの重複が多少気になりますが、まぁとりあえず動かしてみましょう。
(((add3 1) 2) 3) ; => 6
((add3 1) 2 3) ; => 6
(add3 1 2 3) ; => 6
上手く行ってますね。
明示的な curry との併用なんかはどうでしょう? MzScheme の scheme/function ライブラリで提供されているものを使います:
((curry add3 1) 2 3) ; => 6
((curry (add3 1) 2) 3) ; => 6
出来ました。
今度は compose プラス多値と組み合わせてみたり
((compose add3 (lambda (x) (values x 2 3))) 1) ; => 6
((compose (add3 1) (lambda (x) (values x 3))) 2) ; => 6
もいっちょ
((compose (curry add3 1) values) 2 3) ; => 6
良い感じです。
[追記]
年を跨いで、より完全なバージョンを作ってみました。カリー化された無名関数を作るマクロ fn を加え、ライブラリとしての体裁も整えました:
#lang scheme/base
(require (for-syntax scheme/base
(only-in srfi/1 iota split-at)))
(provide fun fn)
(define-for-syntax (make-cases vars body)
(cond ((null? vars) body)
((null? (cdr vars))
#`(lambda #,vars #,body))
(else
#`(case-lambda
#,@(map (lambda (i)
(let-values (((hd tl) (split-at vars (+ i 1))))
#`(#,hd
#,(make-cases tl body))))
(iota (length vars)))))))
(define-syntax (fn stx)
(syntax-case stx ()
((fn (v ...) e ...)
(make-cases (syntax->list #'(v ...))
#'(begin e ...)))))
(define-syntax fun
(syntax-rules ()
((fun (f v ...) e ...)
(define f (fn (v ...) e ...)))))バージョン 4 以降の PLT Scheme では、マクロ展開のフェーズは実行時とは別環境になるので注意が必要です。例えばマクロ展開時にライブラリ関数を使いたい場合は (require (for-syntax ... )) として読み込む必要があります。マクロ用に関数を定義したい場合も、define-for-syntax で定義するか、begin-for-syntax で囲んで define するかしなければなりません。
そういう区別が特に無い処理系では define-for-syntax を普通に define に置き換えれば動くと思います。なお、case-lambda は大抵の処理系でプリミティブもしくは srfi-16 で提供されています。
上で言い忘れたんですが、あくまでも ML スタイル (ラムダ算法においてもそうですが、「全ての関数は1引数関数である」というもの) の模倣ですので、Lisp 的なオプショナル引数やキーワード引数、可変数引数はサポートしません。
マクロの定義上、零引数の関数も作れるようになっていますが、その場合は
(fn () 1) ; => 1
関数ではなく定数が返るようになっています。これは定数を零引数関数と見なす数学の考え方とも一致します。
[追記2]
fn を用いて、既存の関数をカリー化するマクロを作ってみました:
(define-syntax (make-curried stx)
(syntax-case stx ()
((make-curried (f n) ...)
#`(begin
#,@(map (lambda (f n)
#`(define
#,(datum->syntax
f
(string->symbol (format "~a." (syntax-e f))))
#,(let ((args
(map (lambda (_) (gensym))
(iota (syntax-e n)))))
#`(fn #,args (#,f #,@args)))))
(syntax->list #'(f ...))
(syntax->list #'(n ...)))))))こういう風に、関数名と引数の数のペアを指定する方式です (複数可):
(make-curried (map 2)
(+ 2))
(define map-add1 (map. (+. 1)))
(map-add1 '(1 2 3))
; => (2 3 4)(元の関数と同名で定義したかったんですが、再バインドしようとするとエラーになってしまうのであきらめました)
元の関数の arity はどうあれ、指定した個数の引数しか受け取れない関数が作られます:
(+. 1 2) ; => 3 (+. 1 2 3) ; => procedure +.: no clause matching 3 arguments: 1 2 3
case-lambda がエラーを出していますね。
可変数引数やオプショナル引数等は捨てなければいけませんが、関数によってはかなり便利なんじゃないかと思います。
パーサーコンビネータの性能向上について
自前の XML パーサーやウェブ・スクレイピングなどにパーサーコンビネータ・ライブラリを使っているんですが、どうも実行速度が遅いのが気になってきたので、原因を考えてみました。
で、気付いたんですが、例えばこのようなパーサーを定義した時に、
(doP (char #\a) (char #\A) (char #\B))
パーサーを実行する度に (char #\a) のような関数適用が新たに評価されてしまうことが一つの原因ではないかと思いました。
そこで、関数適用の形になっているパーサーは1回だけ評価してキャッシュしておくことで、実行効率の向上を図ることにしました。
(以下 Gauche の PEG ライブラリの実装を参考にさせていただきましたが、少し工夫を加えた部分もあります。)
大まかなイメージとしては、上記のパーサーの場合
(let ((tmp1 (char #\a))
(tmp2 (char #\A))
(tmp3 (char #\B)))
(lambda (input)
...))のような形に展開し、入力ストリームを受け取るラムダの外側にパーサーをキャッシュしておけば良いわけです (内側だと毎回評価してしまいます)。
ただし、上と同じ意味のパーサーでも、次のように変数束縛を伴う定義の場合には問題が生じます。
(doP (a <- (char #\a))
(A <- (char (char-upcase a)))
(char (integer->char (+ (char->integer A) 1))))同じように展開してしまうと
(let ((tmp1 (char #\a))
(tmp2 (char a))
(tmp3 (char (integer->char (+ (char->integer A) 1)))))
(lambda (input)
...))どこにもバインドされていない変数 (a, A) を参照することになり、エラーになってしまうんです。
話を具体的にするために、別の例を出しましょう。引用符に囲まれた文字列を取り出すパーサーを考えてみます:
(doP (q <- (one-of (string->list "\"'")))
(s <- (many-till (none-of (list q))
(char q)))
(return (list->string s)))この場合、1行目のパーサーは意味が変わらないのでキャッシュしたいんですが、2つ目のパーサーは q の値によって意味が変わるので毎回評価しなければいけませんよね。
このように、キャッシュ出来るパーサーと出来ないパーサーがあるわけです。
この問題に対処するため、パーサー式を分析して、doP 構文内で束縛された変数を含む場合はキャッシュしないようにする方法を考えてみました。
bound-identifier=? という関数を使います。
(define (memvar exp vars)
(and (pair? vars)
(let bound? ((exp exp))
(if (identifier? exp)
(ormap (lambda (var)
(bound-identifier=? exp var))
vars)
(let ((exps (syntax-e exp)))
(and (pair? exps)
(ormap bound? exps)))))))syntax-case マクロの中で呼び出す用の関数です。exp はパーサー式、vars は束縛変数のリストで、それぞれ型はシンタックス・オブジェクト、シンタックス・オブジェクトのリストです。
例えば exp として (char a) のような、変数を含む式を受け取った場合、変数 a が vars に含まれていれば #t を返します。
doP 構文を展開する際に束縛変数をリストに集めていき、パーサー式を見つける度に memvar 関数でそのリストと照合することで、束縛変数を参照しているかどうかが分かる仕組みです。
パーサー式が既に変数であるか、または束縛変数を参照していればそのままにしておき、それ以外であれば一時変数としてキャッシュする、という方針で doP 構文をこのように定義してみました:
(define-syntax (doP stx)
(define (finish-body pre-binds var&parsers)
(with-syntax
((parse-it
(let loop ((input #'input) (var&parsers var&parsers))
(if (null? (cdr var&parsers))
(syntax-case (car var&parsers) (return)
((return x) #`(values #f x #,input))
(p #`(p #,input)))
(with-syntax ((input2 (gensym)))
(syntax-case (car var&parsers) (<-)
((v <- p)
#`(receive (err v input2) (p #,input)
(if err
(values err v input2)
#,(loop #'input2 (cdr var&parsers)))))
(p
#`(receive (err v input2) (p #,input)
(if err
(values err v input2)
#,(loop #'input2 (cdr var&parsers)))))))))))
#`(let #,pre-binds
(lambda (input) parse-it))))
(syntax-case stx ()
((doP p ...)
(let loop ((pre-binds '())
(var&parsers '())
(bound-vars '())
(clauses (syntax->list #'(p ...))))
(if (null? clauses)
(finish-body pre-binds (reverse var&parsers))
(syntax-case (car clauses) (<- return)
((return x)
(loop pre-binds
(cons #'(return x) var&parsers)
bound-vars
(cdr clauses)))
((v <- p)
(if (or (identifier? #'p) (memvar #'p bound-vars))
(loop pre-binds
(cons #'(v <- p) var&parsers)
(cons #'v bound-vars)
(cdr clauses))
(with-syntax ((tmp (gensym)))
(loop (cons #'(tmp p) pre-binds)
(cons #'(v <- tmp) var&parsers)
(cons #'v bound-vars)
(cdr clauses)))))
(p
(if (or (identifier? #'p) (memvar #'p bound-vars))
(loop pre-binds
(cons #'p var&parsers)
bound-vars
(cdr clauses))
(with-syntax ((tmp (gensym)))
(loop (cons #'(tmp p) pre-binds)
(cons #'tmp var&parsers)
bound-vars
(cdr clauses)))))))))))以前の実装では doP 構文はモナドの >>= 関数への糖衣構文だったので、パーサーとは独立の純粋に抽象的な定義だったんですが、この変更により doP マクロの中でパーサー連結の詳細を記述しなければいけなくなったのがちょっと残念です。
同じ事の定義が別々の場所にあるのは不自然なので、>>= の定義を逆に doP 構文に依存させるように変更しました:
(define (>>= p f) (doP (x <- p) (f x)))
パーサーコンビネータで作るインタープリタ
ふと、パーサーコンビネータでパーサーを作ると、それをそのままインタープリタとして走らせられるんじゃないか、ということを思い付きました。
普通はファイルやネットワークの入力ポートを
(parse p input-port)
のようにして渡すことで (p はパーサー関数)、パースが行われます。
ここに (current-input-port) を渡してやれば、キー入力を受け取って解析してくれるインタープリタが即出来上がるんじゃないか、という思惑です。
が、実際やってみたところ、ちょっと上手くいきませんでした。
parse 関数の中でポートが遅延リスト (ストリーム) 化されるんですが、どうもそこで eof-object を受け取るまで入力を待ち続ける仕様であるために、パースが終了できないみたいです。
キーボードで eof-object を入力する方法があれば、あるいは、パースに成功したらその時点で入力を待つのを止められれば良いと思うんですが、ちょっとやり方が分かりませんでした。
ということで、単純に read-line で入力を受け取る方式でやってみました:
(require "parser.ss")
(define (prompt)
(printf "~%>>> ")
(flush-output (current-output-port))
(read-line))
(define (repl p)
(let loop ((input (prompt)))
(printf "~s~%" (parse p input))
(loop (prompt))))これに、中置記法の四則演算をするパーサー (arith.ss) を与えてみると:
> (repl (dynamic-require "arith.ss" 'arith)) >>> 1 + 2 3 >>> 1 + 2 * 3 7 >>> (1 + 2) * 3 9
\(^o^)/
実にあっけないですが、パーサー自体が元々評価器としての機能を持っていたためにこういうことが可能なわけです。
ただし read-line を使っているため、1行で完結する式しか受け取れないのが欠点ですね。ちょっと工夫してみました:
(define (append-lines x y)
(cond ((not x) y)
((not y) x)
(else (string-append x (string #\newline) y))))
(define (read-input)
(let loop ((input #f))
(cond ((char-ready?)
(loop (append-lines input (read-line))))
((and input (> (string-length input) 0))
input)
(else
(sleep 0.5)
(read-input)))))read-line の所を read-input に置き換えると、Emacs だと CTRL-j で改行しながら入力できるようになります。
環境というものを持たないので本格的なプログラミング言語は動かせなさそうなのが問題かなと思いますが、解決可能かどうか考え中です。